Site: tv-bbc.com (and its classy older brother, news.tv-bbc.com)
Alternative name: BREAKING NEWS
Imitates: BBC, BBC.com/tv URL, location
Theme: Gaudy half-assery, broken code
Modus Operandi: Facebook Sharebait; real news plagiarism; Mad Libs
Date Created: 29 September 2016
Last Accessed: 12 July 2017
Status: Active (as of 12 July 2017)
Note: Unless otherwise stated, screenshots were taken using the Google Chrome browser with the AdBlcock extension enabled.
Our very first entry in the Fake News Almanac is tv-bbc.com, a fake news website “imitating” the BBC (specifically, the bbc.com/tv domain). I put the word imitating in quotes because the mimicry begins and ends with domain name usage, as we shall soon see.
tv-bbc’s primary method appears to be Facebook sharebait: fear- or rage-inducing headlines, coupled with a legitimate-sounding URL, to be immediately shared by concerned netizens. The more shares a link gets, the increased likelihood of someone actually clicking on the URL, which will take the user to the ad-riddled page.
For instance, a friend of mine shared the following article with another (Fig. 1):
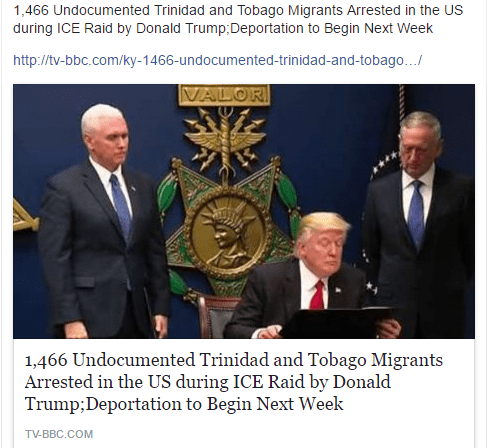
Often, click- and sharebait will target a specific demographic, be it a particular political party, nationality, religion, or other form of identity. In this instance, the headline aims to rattle Trinidad and Tobago immigrants in the United States, as well as any United Statesans who are in favor of more relaxed immigration policies (or are anti-Trump in general).
Actually visiting the site, however, one can see that tv-bbc is absolutely not the BBC. For instance, the site title text for tv-bbc is “BBCTV – Nothing But News”, whereas the actual bbc.com/tv’s is “BBC – TV – Index” (Fig. 2).

As can be further noted in Fig. 3, the real BBC TV isn’t “nothing but news”, but more “we have more than just Doctor Who, but we know that’s what you’re really here for.”
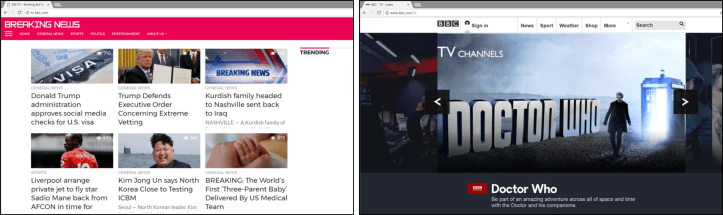
Looking at only the tv-bbc main page (Fig. 4), one can immediately sense that something’s not quite right about this site in general.

For instance, the header for the fake news site simply says “BREAKING NEWS”, instead of the BBC logo. In fact, no where in the body of the page (not considering the HTML) do the letters B, B, and C occur consecutively. They also prefer to use a hot pink instead of a regal red, as is typical of the BBC (or hexadecimal eb0254 and cc0202, respectively, to be precise and anal-retentive).
As you may note, the stories offered up front are all real news, albeit copy-pasta’d from different sources, including the Daily Mail and the Tennessean. In fact, all of the stories on this site are just copied from elsewhere; even the fake stories take real articles and change some of the details, as I will demonstrate later in this post.
I should also note that I took the above screenshot 11 July 2017. Most of these stories happened in January (except the baby story, which happened in September 2016). The page also looks no different than when I last visited back in March. No new news is good new news, though, right?
We can further assess the site by visiting their “About Us” page (Fig. 5).
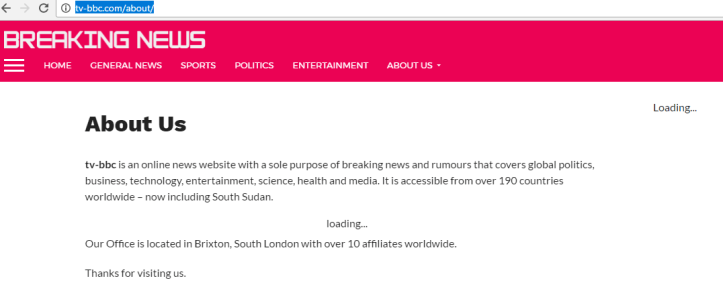
The “Loading…” bits above are where adverts would appear if I did not have AdBlock enabled. Oddly enough, when AdBlock is disabled, the BREAKING NEWS logo disappears. Additionally, shrinking the window size moves the ads from the right sidebar to the bottom of the page. So, uh, props for the responsive design, I suppose.
Aside from ads, the page is fairly sparse. There are no people or organizations mentioned (red flag), just a generic “yeah, we’re a news site, we guess.” They say their “Office [sic]” is in South London, but their IP address says they use Go Daddy to host their site, so we can’t confirm where they’re actually based. We have no idea who these folks are, but they’ve got over 10 affiliates! Worldwide!
We will see such a similar “About Us” page on other fake news sites. (These are probably those aforementioned “affiliates”.)
Also accessible under the “About Us” tab in the menu bar are the “Privacy Policy” and “Contact Us” pages. The Privacy Policy contains a bit about how the user may provide tv-bbc with personally-identifiable information (i.e., name, address, email), which is bizarre because the only part of the site where that would be possible is broken (Fig. 6).
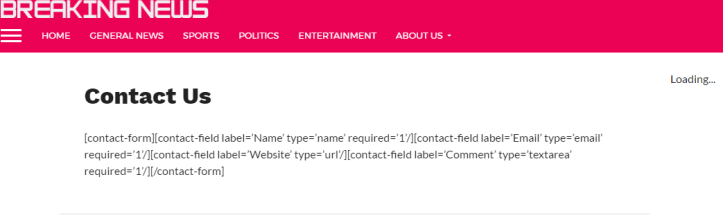
Oh dear. Something tells me that even if this code weren’t broken, I highly doubt there’d be any information provided that would enable the user to contact the good folks at tv-bbc. Broken code is at least an orange flag, in general, when it comes to considering a site’s reputability, but when there is also essentially no information on who is running the site and how to get a hold of them, that’s a ginormous red flag.
Curious about where this code broke and to see if there was potentially any hidden identifying or contact information (there wasn’t), I tried right-clicking into the page so I could view the source. However, my attempts were in vain, as the site owner disabled right-clicking! Instead, a message pops up in a glowy box reading “ALERT: Content is protected !!” (Fig. 7, top). A similar warning appeared when I tried to use Ctrl+U (which allows you to view the page source in Chrome), only it read “ALERT: You are not allowed to copy content or view source” (Fig. 7, bottom).
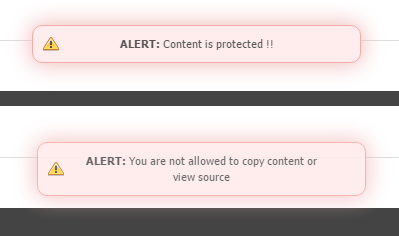
As an aside: Remember when Snopes used to do this? I mean, disable right-clicking and Ctrl+ functions, not put up digital bouncers over broken code and copy-pasta.
You can easily get around this little annoyance by simply using Ctrl+Shift+I (or J), or just pop the URL into Web-Sniffer.net. This is especially useful to keep in mind when you want to copy a sentence and run it through Google to see where else it shows up, since this is a feature implemented across the entire site.
Now, let’s dive into the article that my friend shared, “1,466 Undocumented Trinidad and Tobago Migrants Arrested in the US during ICE Raid by Donald Trump;Deportation to Begin Next Week” (Fig. 8).

First, let’s note the things that are conspicuously absent: author name and article date. If you take away nothing else from this post, remember this: if an article doesn’t have an author and/or date, it’s suspicious. As with the “About Us” and “Contact Us” pages above, if there’s no author, there’s no way to check that individual or group’s credibility. If there’s no date, it essentially makes the story “timeless” in the worst kind of way: the story can be shared at any time, and still seem like “news.”
To tag a date to this particular article: I first dug into this 19 February 2017, and most of the text is ripped from a Washington Post article from 11 February 2017 (more on that in a bit).
Next, let’s look at what’s present. Both above and below the article are icons to share the article on social media or by e-mail; all of these work (though the e-mail icon may not work if you do not have Outlook enabled). There is an icon to comment on the article at the top, but this does not work.
The article itself is 380 words long (text copied through Web-Sniffer.net and pasted into Word, so I didn’t have to count by hand).* Let’s dive on in for a closer look!

Right from the first sentence, we have a few grammatical errors and a ginormous factual error (Fig. 9). While there were a number of arrests of undocumented immigrants, the actual number was around 680 (as reported by Reuters[1]), not 50,000. (For the record, that’s a percent difference of 195%!) I’m not sure where the 50,000 number came from; while it could have been made up from aether, it also may have come from reports on turnout for the “Día Sin Latinos” strike[2], or the population of undocumented people in Philadelphia[3], both numbers reported around early February 2017.
Running this first clause from the first sentence (“As part of the new immigration reforms by President of the United States”, including quotes) through Google (and then selecting “repeat the search with the omitted results included”) pulls up over 300 results of what is essentially the same article, but with the target immigrant group and number of those arrested changed (Fig. 10).
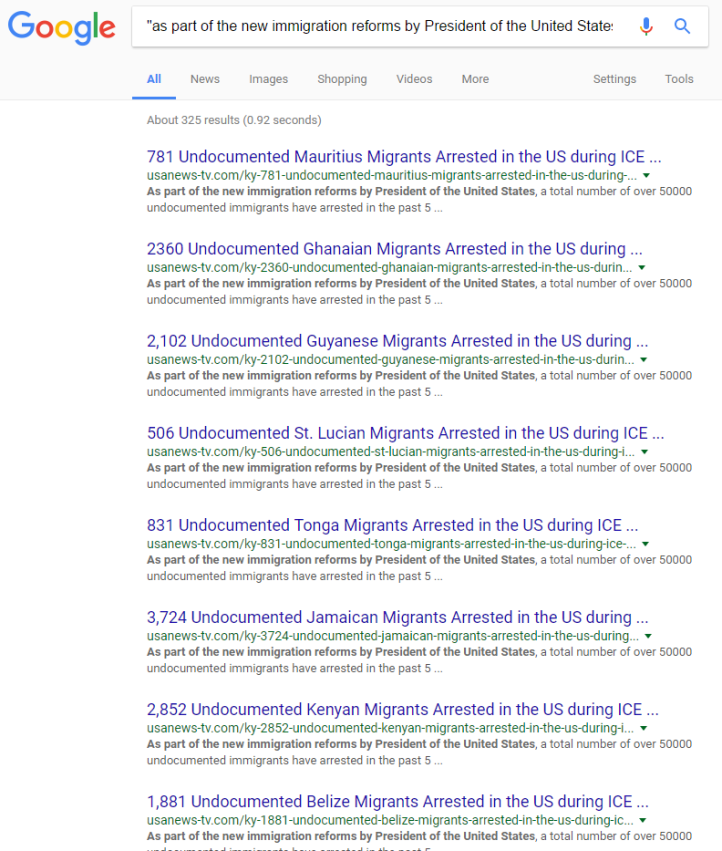
Yes, you can bet your buns I’m gonna cover these other sites. It’s actually not that many more sites, though; most of the results are just different articles (or, I should say, different iterations of the same article) on the same handful of sites.
Moving onto the next paragraph, we see it’s a little more well-written. In fact, contrasted with the first sentence, one might say it’s suspiciously well-written. Googling the phrase “in a series of raids that marked the first large-scale enforcement of President Trump’s” (with quotes) yields a top result of a Washington Post article from 11 February 2017[4].
Using copyscape.com’s comparison tool to compare only the text of the two articles (entering the URLs would also include banner text and links), 78% of the fake article was taken from the Washington Post (WaPo) story (Fig. 11).
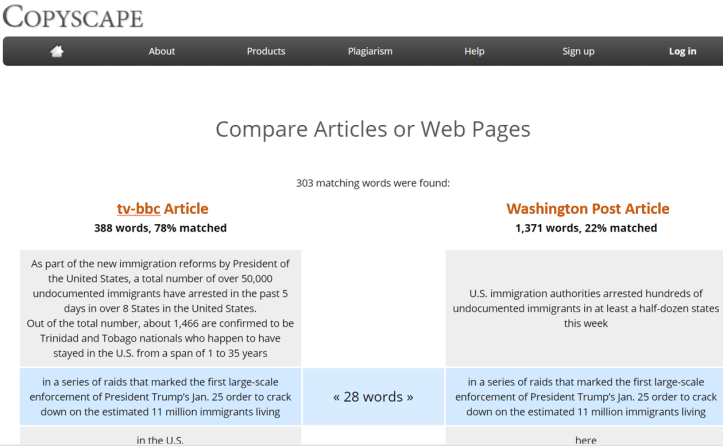
Note that the tv-bbc article is markedly shorter than the WaPo article: 388 vs 1,371 words, respectively. The fake article is essentially a quarter of the original article lifted wholesale, with some additional sentences and word changes. For instance, the first sentence in the fake article adds more details (read: space to place some Mad Libs variables). Additionally, the tv-bbc-ers pulled the classic last-minute-essay-cramming plagiarist trick of replacing words with synonyms (Fig. 12).

Note how the number of people “netted” in the raids increased from “hundreds” (in the WaPo article) to “thousands” (in tv-bbc). The tv-bbc’ers also added “18 African Countries” to those arrested (as opposed to only those from Latin American countries, as per the original WaPo story), and the alarming detail that those arrested would be deported “within 2 weeks”.
In doing research on this fake news site, I stumbled across news.tv-bbc.com, tv-bbc’s classier older brother (Fig. 13), where “classier” means an ill-fitting discount department store suit instead of a tuxedo t-shirt.
I will cover this other tv-bbc/BREAKING NEWS site, as there are a number of differences between this and the one highlighted in this profile. I wanted to point out that another version of this tv-bbc site exists.
Additionally, I found a name to look up. All of the articles on this new site are attributed to a “Charles Nehemiah.” I haven’t done deep research into the name, yet, but so far, I’ve found nothing; however, this is to be expected from a fake news site.
A final note on tv-bbc: the site used to have a box appear in the lower-left corner that would take you to a Facebook page called “World News” (or something along those lines). I thought I hadn’t seen it in doing this most recent research because I was mainly using AdBlock, but it also didn’t appear when I visited the site in Incognito mode.
*While Word counts 380 words in the fake article, Copyscape counts 388, even though they both consider the same body of text. This may be due to the different programs having different definitions of “words.”
Sources:
[1] Ainsley, Julia Edwards and Cooke, Kristina. “Over 680 arrested in U.S. immigration raids; rights groups alarmed.” Reuters. 13 Feb 2017. Web. Accessed 11 Jul 2017. (URL: http://www.reuters.com/article/us-usa-immigration-raids-idUSKBN15S2AQ)
[2] Ortega, Oliver. “After Nationwide ICE Raids, 50,000 People in Milwaukee Rose up to Say the Arrests Were Wrong.” The Progressive. 14 Feb 2017. Web. Accessed 11 Jul 2017. (URL: http://progressive.org/dispatches/after-nationwide-raids-activists-strike-back/)
[3] Eichel, Larry and Ginsberg, Thomas. “Unauthorized Immigrants Make Up a Quarter of Philadelphia’s Foreign-Born.” The Pew Charitable Trusts: Philadelphia Research Initiative. 15 Feb 2017. Web. Accessed 11 Jul 2017. (URL: http://www.pewtrusts.org/en/research-and-analysis/analysis/2017/02/15/unauthorized-immigrants-in-philadelphia)
[4] Rein, Lisa; Hauslohner, Abigail; and Somashekhar, Sandyha. “Federal agents conduct immigration enforcement raids in at least six states.” Washington Post. 11 Feb 2017. Web. Accessed 12 Jul 2017. (URL: https://www.washingtonpost.com/national/federal-agents-conduct-sweeping-immigration-enforcement-raids-in-at-least-6-states/2017/02/10/4b9f443a-efc8-11e6-b4ff-ac2cf509efe5_story.html?utm_term=.df0ac77ac63a)
